There are scenarios where in a network of brokers each broker instance needs to be highly available. For example in hub and spoke architectures it might not be tolerable to be disconnected from the hub broker for a certain amount of time. This would prevent processing messages from spokes in real-time by consumers attached to the hub broker.
Consider an ActiveMQ network of brokers configuration of two nodes where each node also needs to be highly available. To achieve High Availability, each node needs to have a slave broker attached like in the following picture:
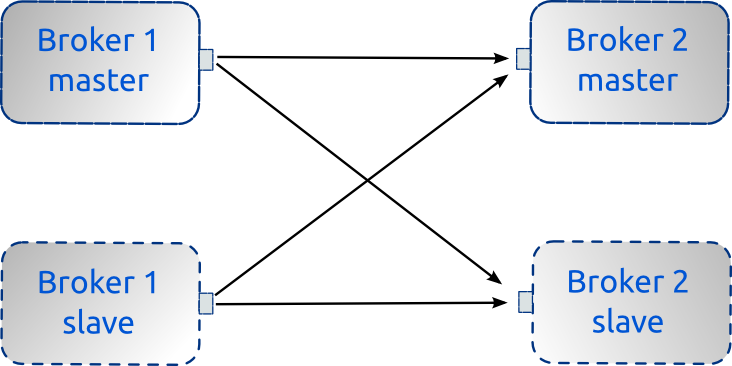
{kind=link}
As shown in the above figure, Master Broker 1 needs to be able to create a network bridge to either Master Broker 2 or in case it is unavailable, Slave Broker 2.
Likewise if Master Broker 1 dies, Slave Broker 1 will take over and it also needs to be able to connect to either Master or Slave of Broker 2.
That way you can achieve high availability of all broker instances in a network of brokers. You already guess that such configuration can become really complex for a larger number of brokers in the network (also depending on the cluster topology).
The configuration of Master/Slave is decently well explained in the ActiveMQ documentation. But how do we configure the brokers network connector so that the network bridge is able to failover to a slave if the master crashes?
When trying to setup a bridge from Master Broker 1 to the master/slave pair of Broker 2, a configuration like
<networkConnector name="NC_1"
uri="static://(tcp://broker2Master:61616,tcp://broker2Slave:61616)"/>
won’t be ideal. Because of the static: url list, the network connector will try to connect to both Master Broker 2 and Slave Broker 2. It will connect to Master Broker 2 just fine but will also retry connecting to Slave Broker 2 forever. Any failed attempt will be logged inside Broker 1 with a warning
WARN | Could not start network bridge between vm://localhost and tcp://broker2Slave:61616 due to: java.net.ConnectExcption: Connection refused.
This does not only pollute the log file and makes it harder to spot any other issues in the log but it also takes some amount of CPU every couple of seconds for trying a reconnect.
Side note: When using static:// in the network connector uri, lost connections will be re-established automatically. On this regards it works like the failover protocol but it tries to connect to all urls in the list.
Instead of trying to connect to all brokers specified in the above network connector uri list (i.e. Master Broker 2 and Slave Broker 2), we only want the bridge to connect to one broker of the list. Therefore a better idea is to use the failover:// protocol inside the network connector configuration. We only want the Master Broker 1 to connect to either Master Broker 2 or Slave Broker 2 but not both. So the configuration now becomes
<networkConnector name="NC_1"
uri="static:failover:(tcp://broker2Master:61616,tcp://broker2Slave:61616)?randomize=false"/>
By also setting randomize=false we will always try connecting to Master Broker 2 first, before attempting to connect to the Slave Broker 2. This configuration will keep trying to connect to one of the two brokers until a connection gets established. It will not try to connect to both brokers in the list!
This configuration however still has a problem.
In case of a connection loss the failover transport will keep trying to reconnect to the specified urls transparently and will not propagate any exceptions up to the higher layer. So if after a crash of the Master 2 broker the Slave 2 broker has finally started up, the tcp transport connection will get re-established transparently by the failover transport in Master Broker 1 without flagging the loss of connection to any higher layers. That implies the broker’s discovery agent that is responsible for creating the network bridge will never be notified and hence will never try to re-create the network bridge (which involves exchanging a couple of messages between brokers).
You can confirm this in jconsole, looking at the bridge MBean. The name of the MBean will refer to the previous master broker whereas the RemoteAddress property got updated with the new master broker.
Prior to version 5.6 the bridge would most likely not work anymore. Things have improved in 5.6 thanks to the fix of AMQ-3542 and the bridge may continue to work but the original problem remains. The bridge need to get re-established after failing over.
So what is needed to re-establish the network bridge after a failover? The solution is to use the failover transport for trying to connect to the urls in the connection list without any reconnects.
When the tcp connection of the bridge is lost, the failover protocol will not try to reconnect but raise an exception to the DiscoveryAgent. The agent will clean up its bridge and ask the underlying failover transport to re-establish a connection to either master or slave of Broker 2. Now the failover transport will try all urls in its list only once, it won't attempt any reconnects on its own. If it still can't connect, it raises an exception back to the agent again, which after a timeout will ask the failover transport again to reconnect. This continues until the failover transport succeeds in connecting to one of the specified urls. Once the tcp connection is established, the DiscoveryAgent can recreate the bridge based on the new connection.
By not letting the failover transport reconnect on its own, the DiscoveryAgent is now aware that the connection of the network bridge got lost (as the error was propagated) and will re-establish the network bridge once the connection got restored.
The failover transport needs to be explicitly configured to not reconnect on its own but raise an exception instead. By default it will reconnect forever.
From version 5.6 onwards, you should use the failover property maxReconnectAttempts=0 for that reason.
So the network bridge configuration finally becomes (for versions 5.6 onwards):
<networkConnector name="NC_1" uri="static:failover:(tcp://broker2Master:61616,tcp://broker2Slave:61616)?randomize=false&maxReconnectAttempts=0"/>
Also from version 5.6 onwards you will be able to use "masterslave:" instead of "static:failover:()". So the above example becomes
<networkConnector name="NC_1" uri="masterslave:(tcp://broker2Master:61616,tcp://broker2Slave:61616)"/>
See AMQ-3564 for more details but "masterslave:" simply maps to
"static:failover:()?randomize=false&maxReconnectAttempts=0"
Prior to version 5.6 you cannot really configure for no reconnects. A value of 0 means "reconnect forever". From version 5.6 the value 0 means "do not reconnect". See the updated failover transport reference.
So for versions < 5.6 instead use maxReconnectAttempts=1 and allow one reconnect, which by default happen within 10 milliseconds (unless configured otherwise using initialReconnectDelay property of the failover transport). This is generally to short for the slave broker to take over.
The network bridge configuration for Slave Broker 1 would be the same as it also needs to connect to either Master Broker 2 or Slave Broker 2.
Summary: When trying to setup a network bridge to a master/slave broker pair, use the failover transport with maxReconnectAttempts=0.
Side note: When the remote broker is shutdown gracefully, the network bridge will get unregistered and closed down so that the discovery agent will always be aware of it. In that case the network bridge will be re-established correctly when the remote broker gets restarted even when not setting maxReconnectAttempts. But it won’t help in case the remote broker crashes.
12 comments:
Will the recommendation works well with 2 masters (network of broker) configuration without slaves?
When you have two masters and no slaves you probably don't want to use failover:// in the network connector uri. You can then just use the static:// uri, without failover.
That way you connect to all brokers in the network connector setup. By using static:// it will also reconnect on any lost connections.
Hey Torsten,
How would it look like if i wanna make a cluster of only 3 Nodes but 2 Master and 3 Slaves?
In this case my Failovers are acctually the same instances
How would the configuration look on the client side?
Thanks for all the feedback.
@Nizar: Not sure I fully understand your question. Do you want to configure one master with two slaves? That is possible but might not necessarily gain you a bigger degree of high availability.
The network connector url can take more than just two nodes, so you could connect to any number of master/slave pairs.
@Anonymous: A full answer depends on your use case. However as each node in the brokers network is already highly available, you could connect each client to only one master/slave broker pair. That way you can manually partition the load (all clients) over all brokers.
E.g. assuming you want to connect clientA to the first node in the brokers network, it could use the following url:
failover:(tcp://broker1Master:61616,tcp://broker1Slave:61616)?maxReconnectAttempts=1;randomize=false
Hi Thorsten
For the final network bridge configuration you set randomize=true. Any reason this should be randomized?
Thanks ML, that was an oversight on my side. You most likely want to go with randomize=false, assuming your master will be up and running for the vast majority of times.
Just found
http://fusebyexample.blogspot.com/2011/11/activemq-network-of-master-slave-broker.html
which mentions the new masterslave:
I know how to configure Master/Slave configuration paired with two hosts in a shared file system. Failure of a host, will failover to slave in the other host, and becomes master. When will the old master become master after the recovery? Will it happen automatically?
The old master will become a slave when restarting it and will run as a slave until the new master gets shutdown or crashes. The old master then takes over as the new master again.
Thank you Torsten,
With respect to the question above, what if we set randomness = false and set master URI first. Will master take over in the next re-connection provided master is available. I have a Scenario with master slave paired with 2hosts. something like master1, slave2 with hostA and Master2 slave1 in hostB. Here load in these queues are in millions. So if a host reboots the system should be able to go back to the load balancing state. i.e. one master working in each host.
@CIJO:
If one of the two machines gets rebooted, lets assume hostB, then both masters will run on hostA (given your setup).
Once your hostB has fully rebooted, the brokers on hostB will both run as slaves and will continue so until one of the masters on hostA gets shutdown or crashes.
In order to restore you original setup, you may want to manually stop one broker on hostA so that the corresponding slave broker on hostB takes over and becomes a master.
Then you will have a master and a slave on each host again.
Post a Comment